

Introduction
The sed command in Linux is a very useful tool for working with text. It helps you edit and change text automatically without opening files in editors like nano or vim.
This is very helpful when you are working with large log files, configuration files or scripts. In real jobs like DevOps system administration and scripting people often need to repeat the same changes many times.
Doing this manually takes a lot of time and effort. Sed solves this problem by letting you make changes with just one simple command.
This guide is written in very simple words so beginners can understand it easily. It explains step by step how things work and also gives simple examples.
The main goal is not only to learn commands but to understand how sed is used in real world work.
What is the sed Command?
The sed command stands for:
Stream Editor
A stream editor is a simple tool that reads text one line at a time and processes it like a continuous flow of data.
It takes each line, applies the required changes and then shows the updated result.
Unlike normal text editors it does not open files in a window and you do not edit anything manually by clicking or typing inside an editor.
Instead sed works in the background automatically it reads the file, makes changes and prints the final output.
In simple words used is a tool that edits text automatically using commands.
For example if you have a large log file with thousands of lines and you want to replace a word like error with warning you do not need to edit each line one by one.
You can simply run one sed command and complete the task in seconds.
This is why sed is considered a very useful tool for saving time and automating text changes.
Why sed is Important in Linux
Understanding sed is important because it is used in many real-world tasks.
Here are some common situations where sed is used:
- Cleaning log files
- Updating configuration settings
- Replacing text in multiple files
- Removing unwanted lines
- Formatting data
- Automating repetitive tasks
- Processing large datasets
In production servers, automation is very important. Commands like sed help administrators manage systems efficiently and reduce human errors.
Key Features of sed
The sed command provides many powerful features that make it useful in everyday Linux work.
- Search and replace text automatically
- Edit files without opening them
- Delete or insert lines
- Support for regular expressions
- Process multiple files at once
- Work with pipelines and scripts
- Handle large files efficiently
These features make sed one of the core tools in Linux text processing.
Basic Syntax of the sed Command
The basic syntax of the sed command is:
sed [options] ‘command’ file
Let’s understand each part clearly.
- sed → The command name
- options → Control how the command works
- command → The action to perform
- file → The input file
Think of it like this:
sed → What tool to use
options → How to run it
command → What action to perform
file → Where to apply it
Example:
sed ‘s/hello/world/’ sample.txt
This command searches for the word hello and replaces it with world.
Understanding the Substitute Command (s)
The most commonly used operation in sed is substitution.
Syntax:
s/old/new/
Explanation:
- s → substitute (replace)
- old → text to find
- new → replacement text
Example:
sed ‘s/apple/mango/’ file.txt
If the file contains:
I like apple
Output:
I like mango
Important note:
By default sed only replaces the first match in each line. This means if a word appears many times in one line only the first one will be changed. This is done to avoid unwanted changes in the text. If you want to replace every match in a line you need to use a special option called the global flag
Replace All Occurrences Using Global Flag
To replace every occurrence in a line, use the g flag.
Command:
sed ‘s/apple/mango/g’ file.txt
Meaning:
- g = global replacement
Without g:
apple apple apple
Output:
mango apple apple
With g:
mango mango mango
This small flag makes a big difference in real-world automation tasks.
In-Place Editing (Permanent Changes)
Normally, sed only shows the output on the screen. It does not modify the original file.
To permanently change the file, use:
sed -i ‘s/Linux/Unix/g’ file.txt
Here:
-i = in-place editing
This means the file will be updated directly.
Important best practice:
Always test the command first without -i to make sure the result is correct.
Create Backup Before Editing
When working on important files, it is safer to create a backup.
Command:
sed -i.bak ‘s/Linux/Unix/g’ file.txt
This command will:
- Modify the file
- Create a backup copy
Example backup file:
file.txt.bak
This is very useful in production environments where mistakes can cause serious issues.
Delete Specific Lines
You can delete lines using the d command.
Example:
sed ‘2d’ file.txt
Meaning:
Delete line number 2.
If the file contains:
Line 1
Line 2
Line 3
Output:
Line 1
Line 3
This feature is commonly used to remove unwanted data from files.
Delete Multiple Lines
Command:
sed ‘2,4d’ file.txt
Meaning:
Delete lines from 2 to 4.
This is very useful when you want to remove certain parts of data from configuration files or log files
You can delete lines based on a specific pattern or word instead of using line numbers
This makes it easier to find and remove unwanted lines automatically
Delete lines matching a pattern
You can tell the tool to remove all lines that contain a particular word or pattern
This saves time and helps manage large files more easily
Command:
sed ‘/error/d’ logfile.txt
Meaning:
Delete every line that contains the word error.
Real-world example:
Cleaning system logs by removing error messages.
Print Specific Lines
Sometimes you only want to display certain lines.
Command:
sed -n ‘1,3p’ file.txt
Explanation:
- -n → hide normal output
- p → print selected lines
This command prints only lines 1 to 3.
This feature is helpful when analyzing large files and focusing on specific sections.
Insert Text Before a Line
Command:
sed ‘2i This is new line’ file.txt
Meaning:
Insert text before line 2.
Use case:
Adding headers to configuration files.
Append Text After a Line
Command:
sed ‘2a This is appended text’ file.txt
Meaning:
Add text after line 2.
This is commonly used in scripts to add new configuration values.
Replace Entire Line
Command:
sed ‘2c This is replaced line’ file.txt
Meaning:
Replace the entire content of line 2.
This is useful when updating outdated configuration settings.
Remove Empty Lines
Command:
sed ‘/^$/d’ file.txt
Explanation:
- ^$ → empty line
- d → delete
This command is used to remove empty lines from a file
Cleaning a file in this way makes it easier to read and understand
It also helps reduce the file size by removing unnecessary spaces
Replace text at the beginning of a line
You can also use commands to change text that appears at the start of each line
This is useful when you want to update prefixes or standardize the format of a file
Command:
sed ‘s/^Linux/Unix/’ file.txt
Meaning:
Replace the word only if it appears at the start of the line.
Symbol:
^ = beginning of line
This allows precise control over replacements.
Replace Text at the End of a Line
Command:
sed ‘s/error$/warning/’ file.txt
Symbol:
$ = end of line
This ensures the replacement happens only at the end.
Case-Insensitive Replacement
Command:
sed ‘s/linux/Unix/I’ file.txt
Meaning:
Replace text regardless of uppercase or lowercase.
Matches:
- linux
- Linux
- LINUX
This is helpful when working with inconsistent data.
Replace Text in a Range of Lines
Command:
sed ‘1,3 s/Linux/Unix/’ file.txt
Meaning:
Replace text only between lines 1 and 3.
This prevents changes in other parts of the file.
Extract Lines Between Two Patterns
Command:
sed -n ‘/start/,/end/p’ file.txt
Meaning:
Print lines between:
start
and
end
This is useful for extracting sections from logs or reports.
Process Multiple Files
Command:
sed -i ‘s/old/new/g’ file1.txt file2.txt file3.txt
This command updates multiple files at once.
In automation scripts, this saves a lot of time.
Real-World Examples
Example 1: Clean Log File
sed ‘/error/d’ system.log
Removes error messages from logs.
Example 2: Update Port Number
sed -i ‘s/8080/9090/’ config.conf
Changes application port.
Example 3: Remove Comments
sed ‘/^#/d’ config.conf
Deletes comment lines.
Example 4: Extract Only Errors
sed -n ‘/ERROR/p’ logfile.txt
Shows only error lines.
Performance Tips for Large Files
When working with large files, performance becomes important.
Tip 1: Use -n to Reduce Output
sed -n ‘/pattern/p’ largefile.txt
This reduces unnecessary processing.
Tip 2: Combine Commands
Instead of running multiple commands separately, combine them.
sed -e ‘s/error/warning/’ -e ‘/debug/d’ file.txt
This improves efficiency.
Tip 3: Use Pipes
cat file.txt | sed ‘s/error/warning/’
Pipes allow direct data processing.
sed in Shell Scripts
Example script:
#!/bin/bash
sed ‘s/foo/bar/g’ input.txt > output.txt
This script automatically replaces text.
Automation scripts like this are widely used in DevOps and system management.
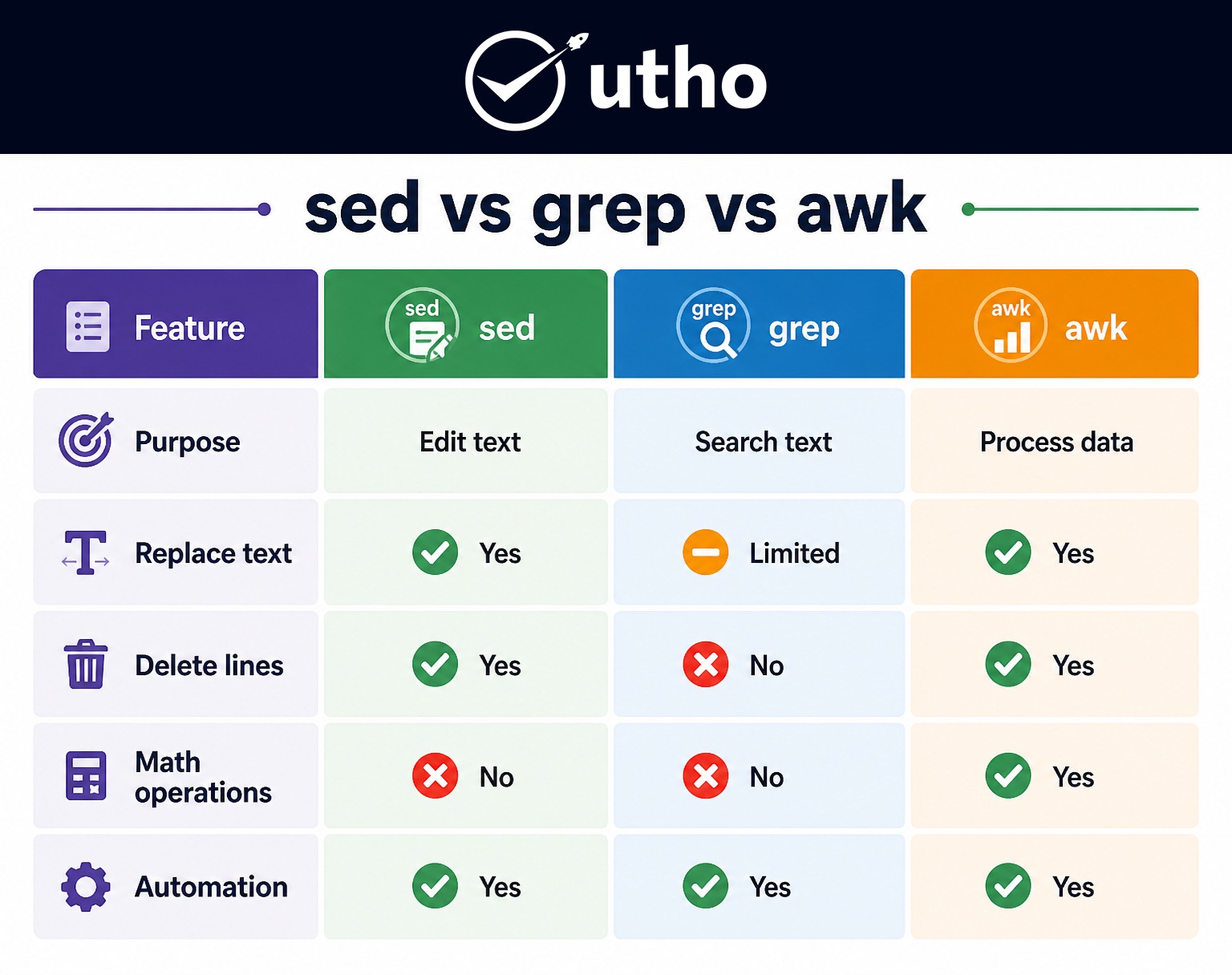
Best Practices for Using sed
- Always test commands first
- Create backup files
- Use simple commands
- Combine operations
- Use regular expressions carefully
Following these practices prevents errors and improves reliability.
The sed command is a very useful tool in Linux for working with text. It helps you do text changes automatically without doing it by hand. It is also very fast and works well with big files. You can use it directly from the command line.
Learning sed is very important for anyone working with:
- Linux
- DevOps
- System Administration
- Shell Scripting
Once you master sed, many daily tasks become faster and easier.





